

データマイニングとは?事例・分析手法・医療分野での応用を解説 #014

2022.04.06
2025.03.27
データマイニングは、膨大なデータの中からクラスタリングやマーケット・バスケット分析などの手法を使って、有益な情報を取り出す技術のことです。小売業や金融、医療など、さまざまな分野で活用されています。
この記事では、データマイニングの概要や歴史、やり方を解説。分析手法や活用事例も紹介しています。
目次
データマイニングとは
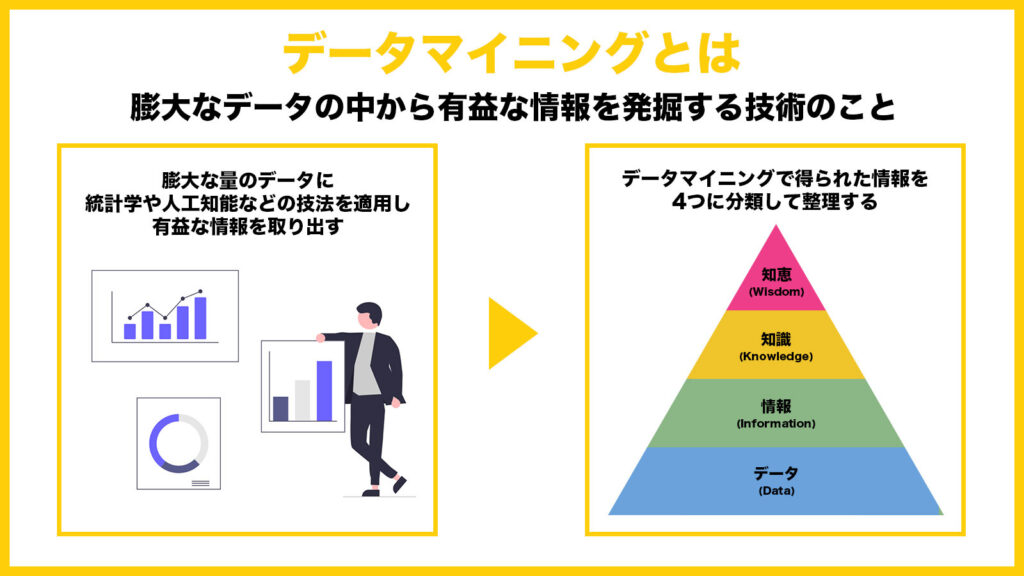
「データマイニング(data mining)」とは、 わかりやすく言うと、その言葉のとおり膨大なデータ(data)の中から情報を発掘する(mining)技術のことです。
構造化された膨大な量のデータ(ビッグデータ)に、統計学や人工知能(AI)、パターン認識などの技法を網羅的に適用することで有益な情報を取り出すことができます。
データマイニングの歴史
1989年に確立された学術研究分野「Knowledge Discovery in Databases」がデータマイニングの元祖といわ言われています。「Knowledge Discovery in Databases」は、膨大なデータからマイニングの技法を使って有益な情報を取り出すことです。頭文字を取って「KDD」と略されることもあります。
1990年代になると、計算機の性能が大幅に向上しました。それに伴い、「Knowledge Discovery in Databases」の研究も加速。研究者によってデータマイニングの定義や基本性能、処理の手順が提案されるようになります。
2000年代になると、一般家庭もインターネットを常時接続するようになったため、インターネット上のデータが膨大な量となります。データを効率よく分析するために、IT企業を中心としてデータマイニングが導入されるようになり、また、SNSの普及も手伝って、データの分析を専門とする企業も出てくるようになりました。
データマイニングの種類
データマイニングには「仮説検証」と「知識発見」の2種類があります。
以下では、「仮説検証」と「知識発見」について解説します。
- 仮説検証
仮説検証とは、事前に立てた仮説を基に検証したい課題や事象の解決に必要なデータを集めて、適切な手法で分析することです。
仮説立てと欲しい分析結果を得るための分析手法の選択は、人間がする必要があります。そのため、統計学などの知識を持った人が必要です。ただし、データマイニングツールによっては、ある程度の専門知識を補ってくれる場合があります。
仮説検証ではあくまで仮説に基づいた分析が行われるので、想定外の結果が導かれることはありません。しかし、そもそも最初に立てた仮説が誤っている可能性があります。そのため、仮説の検証と分析、分析結果の読み解きを繰り返します。実際の分析現場では、さまざまな分析方法を組み合わせて、結果を導き出すのが一般的です。
なお、仮説検証のデータマイニングの手法には、どの地域でどの商品がどれくらい売れているかといった売上高・売上個数を推測する「量的変数」や、地域別に売れている商品や商品カテゴリーを抽出して分類・整理する「質的変数」などがあります。 - 知識発見
知識発見では事前に仮説を立てずに集めたデータから新しいパターンやルール、類似性などの知識を自動的に見つけ出します。
知識発見はビッグデータに対して有効で、主に「機械学習」で活用されています。機械学習では人工知能(AI)を活用しており、コンピューター自体が学習をしながら相関関係などを導き出します。AIによって、人間が想定していなかったり、見過ごしていたりする相関の発見が可能です。
また、ある事象における原因の特定や複雑な条件が絡む課題の最適化もできます。ただし、データ自体に関連性がなければ有益な結果を得ることはできません。
なお、知識発見のデータマイニング手法には、データをグループごとに分ける「クラスタリング」や、データの中から関連性を見つけ出す「マーケット・バスケット分析」などがあります。
データマイニングで得られるもの
データマイニングで得られる知識は、以下の4つに分類して整理するのが一般的です。
- データ(Data):整理や分類がされていない数値
- 情報(Information):データを整理・分類したもの
- 知識(Knowledge):情報から得られる傾向や知見
- 知恵(Wisdom):知識を利用して人が判断する
データマイニングで得られる情報は、それぞれの頭文字を取って「DIKWモデル」と呼ばれています。データよりも情報、情報よりも知識、知識よりも知恵というように、下にいくほど有益性が高いと判断されます。
データマイニングによってデータの収集や整理・分類、知識を得ることが可能ですが、得た知識を知恵として活用するには人の判断力が必要です。
データマイニングでできる3つのこと
データマイニングでできるのは、「データの分類」「データの予測」「関連するデータの発見」の3つです。
1.データの分類
収集したデータに条件を設定して、分類・整理をします。たとえば、商品の売上数量や売上金額、純利益などへ分類や整理ができます。
これを「ただグループごとに分けているだけ」と捉える人もいますが、データマイニングで扱う元のデータ量は膨大です。膨大なデータを人力でグループごとに分けるのは難しいでしょう。膨大なデータが無秩序に並んでいるのと、グループごとに分類・整理されているのとでは情報の扱いやすさが大きく異なります。
データの分類・整理をするだけでも情報は活用しやすくなるため、マーケティング施策を考えやすくなるメリットがあります。
2.関連するデータの発見
収集したデータの中から、同時発生や相関関係などの関連性を発見します。
データマイニングをすることで、同じタイミングで購入される商品や同じ時期に売上がアップする商品などが分かります。なかには、人が気付かなかった商品の関連性や季節・天候の影響なども判明することがあります。
3.データの予測
収集したデータの事象と関連性を分析することで、特定の事象が発生する確率や発生要因を明確にします。たとえば、寒くなると売れる商品があれば、秋から冬にかけて売上はアップすると予測できるでしょう。また、Aの商品とBの商品が一緒に売れるのであれば、Bの商品に類似する新商品のCもAの商品と一緒に売れるかもしれないという予測が可能です。
なお、感覚的に予測するのと収集したデータを基に予測するのでは、大きな違いがあります。
たとえば、「寒くなるとホットコーヒーが売れる」と「気温が〇度以下になるとホットコーヒーが売れる」では、予測の根拠となる事実がある後者のほうが、より的確な戦略が打てます。
データマイニングの活用事例
データマイニングは、さまざまな業界で活用されています。以下では、データマイニングを活用している業界とその活用方法について紹介します。
小売業
小売業では、データマイニングで得られた情報をマーケティング施策で生かすことがあります。
顧客のデータや天候、曜日、時間帯、販売実績などを分析することで、いつ・どんな商品がどれくらい売れているかの把握が可能になります。これらの情報から商品の仕入れ時期や量を調節するなど、効果的なアプローチができます。
また、顧客の好みにあった商品をスマートフォンのプッシュ通知でおすすめしたり、キャンペーンをダイレクトメールで配信したりといった方法で活用している小売業者もあります。
製造業
製造業では、おもに製造機器の設備管理のためにデータマイニングを活用しています。
たとえば、いつ・どの箇所に・どういったタイミングで不具合や故障が生じるか、把握することが可能です。そのため、適切なタイミングで点検や設備交換ができます。
さらに、この分析した情報を製造機器を設計する段階で生かせば、故障しづらいだけでなく効率化を図った機器が作れるようになります。
金融業
金融機関では顧客データのほかに、数十億円規模の取引データを保有しています。これらのデータをマイニングすることで、盗難・スキミングといった不正利用の検知が可能になるのです。もしも問題が発生した際には、顧客にすぐに連絡をして状況を確認し、リスク回避や迅速な問題解決へ繋げられます。
また、見込み顧客へ向けたローンや投資信託などの金融商品の販売促進のほか、既存顧客の解約予測とその対策も可能です。さらに、市場リスクの的確な把握や融資先が債務不履行をする確率も予測できます。
教育
学習の進捗状況やテストの結果などを分析することで、生徒が得意・不得意としている教科や内容の把握、各生徒の理解度を把握できます。生徒を理解度別にグループ分けして、レベルに合った指導をしたり、成績を伸ばすための個別対策を考えたりすることも可能です。
また、データマイニングによって、現時点の生徒の成績が今後どのように推移するかを予測することもできます。
保険
生命保険や損害保険といった、保険業界でもデータマイニングは活用されています。
たとえば、生命保険の場合は顧客の性別や年齢、疾患、罹患率、回復までの日数、医療費などを分析。自動車保険の場合は、事故が発生する確率、運転者の年齢、自動車の車種やグレード、損害補償額などを、火災保険の場合は、火災が起こる確率、居住年数、被害にあった住居・家財道具といった保険対象品、原状回復費用などを分析します。
これらのデータを分析することで関連性が把握でき、保険料の算出に生かせます。
データマイニングのやり方
データマイニングは、収集・加工・分析の順番で行われます。
1.データを収集する
まずは、データマイニングをするためにデータを集めます。
データ量が多いほど信憑性の高い情報が得られるため、できるだけ多く集めるのがポイントです。ただし、大量のデータを集めれば良いというわけではありません。目的に合ったデータを集めることで、効率的にデータマイニングができます。
はじめにデータマイニングをする目的を決めてから、目的に合ったデータを集めるようにしましょう。
2.収集したデータを加工する
収集した直後のデータには、分析の妨げとなるノイズが含まれています。また、決まった形式でないとデータの読み込みができません。
そのため、ノイズの除去やデータ形式を統一する「データクレンジング」をします。
3.データを分析する
後述する「クラスタリング」「ロジスティック回帰分析」「マーケット・バスケット分析」といった手法を用いて、データ分析をします。
分析後は分析結果について要因を特定し、ほかのデータでも当てはまるか検証をします。
データマイニングにおける代表的な3つの分析手法
データマイニングでは、主に「クラスタリング」「ロジスティック回帰分析」「マーケット・バスケット分析」といった手法が用いられます。
1.クラスタリング
クラスタリングは、データを類似性に基づいてグループ分けする手法のことです。分けられた各グループは、クラスタと呼ばれます。
クラスタリングは、顧客セグメントを作る際によく用いられる手法です。クラスタリングをすることで、特定の顧客に効果的なキャンペーンの展開や、商品・サービスの紹介が可能になります。
2.ロジスティック回帰分析
ロジスティック回帰分析は、特定の事象が起きる確率を予測する手法のことです。たとえば、キャンペーンを展開した際に、顧客が購入してくれる確率などを予測します。
あくまで予測になるため、実際の結果とは異なる場合もありますが、予測をしたほうが無駄なく施策を打てます。
3.マーケット・バスケット分析
マーケット・バスケット分析は、一緒に購入される商品の組み合わせを発見する手法のことです。
マーケット・バスケット分析をすることで、「ハンバーガーを買う顧客は、ポテトも一緒に買う」というような関連性はもちろん、「オムツを買う顧客は、ビールも一緒に買う」など、思いがけない関連性を見つけることができます。
医療分野でデータマイニングを活用しよう
医療分野でデータマイニングを活用することで、得られた情報を診療や研究などの場面で応用できます。
たとえば、「〇〇の病気に罹っている患者は、△△も併発する恐れがある」「〇〇の特徴がある患者は、△△を発症する可能性がある」など、これまで熟練の医師の感覚や経験などによって培ってきた治療方法をデータマイニングによって発見できるようになります。なかには、これまで誰も想像しなかった関連性も発見できるでしょう。そのため、経験の浅い医師も正確な診断が可能となるのです。
また、患者数や疾患パターン、薬の処方量、処方日数を分析することで、併用数の多い薬や併発疾患も把握できます。製薬会社や医療材料・機器メーカーは、これらの情報を応用して薬剤の処方動向や市場把握といったマーケティングの場面で活用可能に。フィールド調査や開発品目同薬効の現状把握といった開発の場でも活用できます。
メディカル・データ・ビジョン株式会社では、医療機関や製薬会社に向けて、データ解析をサポートするツールやサービスを提供しています。
日本最大規模の診療データベースをもとに、お客様自身で患者数や処方日数、処方量などの分析が可能です。マーケティングや開発などでデータの活用を検討されている場合は、ぜひお気軽にお問い合わせください。